语音合成 (TTS)
安装所需的依赖并在 conf.yaml 进行配置后后,通过修改 conf.yaml 中的 TTS_MODEL 选项来启用相应的语音合成引擎。
sherpa-onnx(本地 & 推荐)
自
v0.5.0-alpha.1版本起可用(PR#50)
sherpa-onnx 是一个强大的推理引擎,支持多种 TTS 模型(包括 MeloTTS)。项目已内置支持,默认使用 CPU 推理。
配置步骤:
- 从 sherpa-onnx TTS models 下载所需模型
- 参考
config_alts中的配置示例修改conf.yaml
如需使用 GPU 推理(仅支持 CUDA),请参考 CUDA推理。
Piper TTS(本地 & 轻量快速)
Piper 是一个快速、本地化的神经网络文本转语音系统,支持多种语言和声音。使用预训练的 ONNX 模型,可在 CPU 上实现实时语音合成。
安装步骤
- 安装 piper-tts:
uv pip install piper-tts
-
下载模型文件:
- Piper 需要使用经过训练的 ONNX 模型文件来进行语音生成
- 推荐模型:
zh_CN-huayan-medium- 中文(普通话)en_US-lessac-medium- 英文ja_JP-natsuya-medium- 日文
- 下载方式:
-
方式一:手动下载
- 中文模型:https://huggingface.co/csukuangfj/vits-piper-zh_CN-huayan-medium/tree/main
- 其他模型:在 Hugging Face 搜索 "piper" 或自行训练
-
方式二:使用命令自动下载(不推荐)
python -m piper.download_voices zh_CN-huayan-medium
-
- 文件存放:
- 下载
.onnx和.onnx.json两个文件到models/piper/目录
- 下载
-
在
conf.yaml中配置:
piper_tts:
model_path: "models/piper/zh_CN-huayan-medium.onnx" # ONNX 模型文件路径
speaker_id: 0 # 多说话人模型的说话人 ID(单说话人模型使用 0)
length_scale: 1.0 # 语速控制(1.0 为正常速度,>1.0 更慢,<1.0 更快)
noise_scale: 0.667 # 音频变化程度(0.0-1.0)
noise_w: 0.8 # 说话风格变化程度(0.0-1.0)
volume: 1.0 # 音量(0.0-1.0)
normalize_audio: true # 是否标准化音频
use_cuda: false # 是否使用 GPU 加速(需要 CUDA 支持)
- 在
conf.yaml中设置tts_model: piper_tts
特点
- ✅ 完全本地化,无需网络连接
- ✅ CPU 实时推理,速度快
- ✅ 支持多种语言和声音
- ✅ 支持 GPU 加速(可选)
- ✅ 模型文件小,易于部署
如需更多模型选择,可访问 Piper 语音样本页面 试听并下载不同语言和声音的模型。
pyttsx3(轻量快速)
简单易用的本地 TTS 引擎,使用系统默认语音合成器。使用 py3-tts 而不是更著名的 pyttsx3,因为 pyttsx3 似乎无人维护,且在测试电脑上无法运行。
配置步骤:
- 执行
uv pip install py3-tts安装 - 在
conf.yaml中设置tts_model: pyttsx3_tts
-
- 使用命令
uv pip install py3-tts安装。
- 使用命令
-
- 这个 TTS 引擎没有任何配置项,直接在
conf.yaml中设置tts_model: pyttsx3_tts即可。
- 这个 TTS 引擎没有任何配置项,直接在
这个包将使用您系统上的默认 TTS 引擎:
- Windows 使用 sapi5 引擎
- macOS 使用 nsss 引擎
- 其他平台使用 espeak 引擎
MeloTTS(本地部署)
- 强烈推荐通过 sherpa-onnx 使用 MeloTTS,而非安装较为复杂的官方版本
- MeloTTS 与 Coqui-TTS 存在依赖冲突,请勿同时安装
- MeloTTS 官方版本在 macOS 上可能出现 mps 相关错误(欢迎提供解决方案)
安装步骤
从项目
v1.0.0版本开始,我们采用uv管理依赖,这大大简化了 MeloTTS 的安装流程。
- 安装 MeloTTS 和必要组件:
# 安装 MeloTTS
uv add git+https://github.com/myshell-ai/MeloTTS.git
# 下载 unidic
python -m unidic download
- 下载额外依赖:
# 进入 Python 解释器
python
# 下载必要的 NLTK 数据
>>> import nltk
>>> nltk.download('averaged_perceptron_tagger_eng')
# 完成后按 Ctrl+D 退出解释器
- 配置启用:
- 编辑项目的
conf.yaml文件 - 将
tts_model设置为melo_tts
补充说明
- 官方文档:MeloTTS Installation Guide
- 如遇到
mecab-python相关问题,可尝试使用此分支(注:截至 2024/7/16 尚未合并至主分支)
Coqui-TTS(本地部署)
- MeloTTS 与 Coqui-TTS 存在依赖冲突,请勿同时安装
Coqui-TTS 是一个开源语音合成工具包,支持多种模型和语言。推理速度取决于所选模型的大小和复杂度。
安装步骤
# 安装 Coqui-TTS 及其语言支持
uv add transformers "coqui-tts[languages]"
模型配置
- 查看可用模型:
uv run tts --list_models
- 在
conf.yaml中配置:
coqui_tts:
# 要使用的 TTS 模型的名称。如果为空,将使用默认模型
# 执行 "tts --list_models" 以列出 coqui-tts 支持的模型
# 一些示例:
# - "tts_models/en/ljspeech/tacotron2-DDC"(单说话人)
# - "tts_models/zh-CN/baker/tacotron2-DDC-GST"(中文单说话人)
# - "tts_models/multilingual/multi-dataset/your_tts"(多说话人)
# - "tts_models/multilingual/multi-dataset/xtts_v2"(多说话人)
model_name: "tts_models/en/ljspeech/tacotron2-DDC" # 模型名称
speaker_wav: "" # 参考音频文件路径
language: "en" # 语言
device: "" # 设备
-
单语言模型:
- 默认配置为英文单语言模型
- 如需中文支持,请更换为中文模型 (如
tts_models/zh-CN/baker/tacotron2-DDC-GST)
-
多语言模型:
speaker_wav:参考音频文件路径- 支持相对路径(如
./voices/reference.wav) - Windows 使用绝对路径时注意将
\改为\\ - 确保参考音频文件存在于指定位置
- 支持相对路径(如
language:设置优先使用的语言- 中文设置为
"zh" - 英文设置为
"en" - 此参数与
speaker_wav对应
- 中文设置为
GPTSoVITS(本地部署,性能适中)
在 PR #40 中引入,于 v0.4.0 版本正式发布
GPT-SoVITS 是一个强大的语音合成引擎,可实现高质量的声音克隆。
GPTSoVITS的官方教程目前尚不完善。 以下部分内容整理��自 QQ 群的 腾讯文档,由v1.0.0版本发布前 QQ 群的用户们共同编辑完成(文档因不明原因被腾讯封锁,现已停止维护)。若您在阅读过程中遇到问题,或希望参与教程完善,可通过本页面最下方的编辑按钮提交修改建议,也可直接联系我进行反馈。
GPTSoVITS-V2 整合包
米哈游一键包
如果你是用的米哈游一键包:
先启动 GPT SoVITS,然后启动本项目 (uv run run_server.py)。
需要修改以下设置:
1: conf.yaml里的tts选项改成GPT_Sovits(应该没人会忽略这步吧)
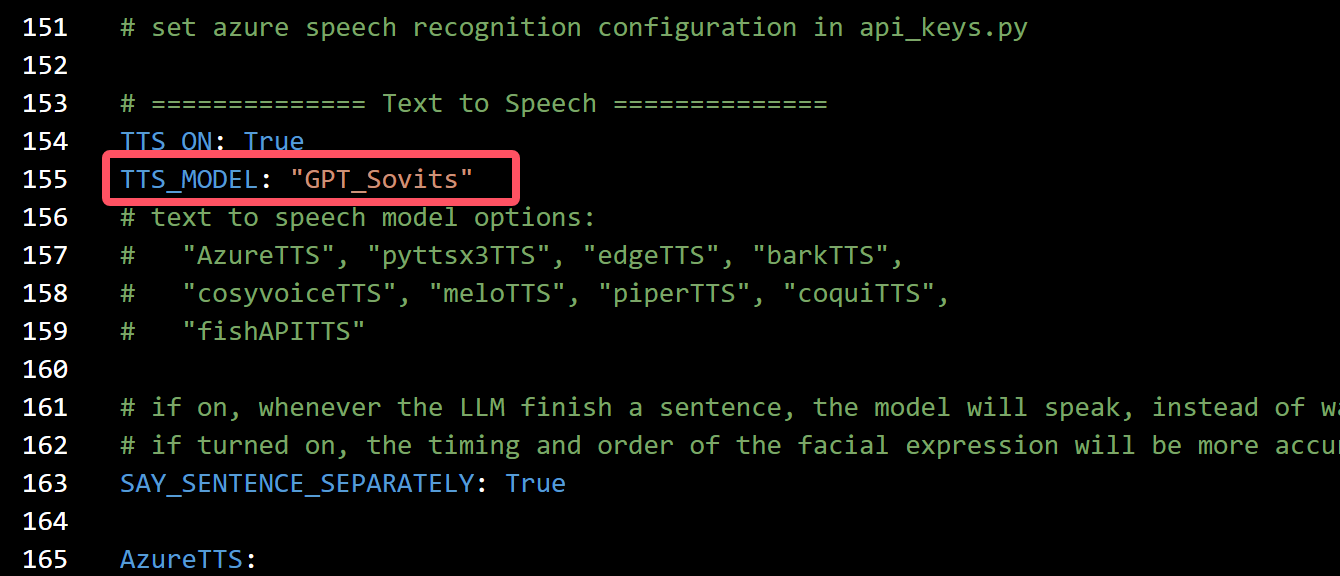
- 这个截图是在
v1.0.0版本之前截的图,请填入gpt_sovits,不要填GPT_Sovits
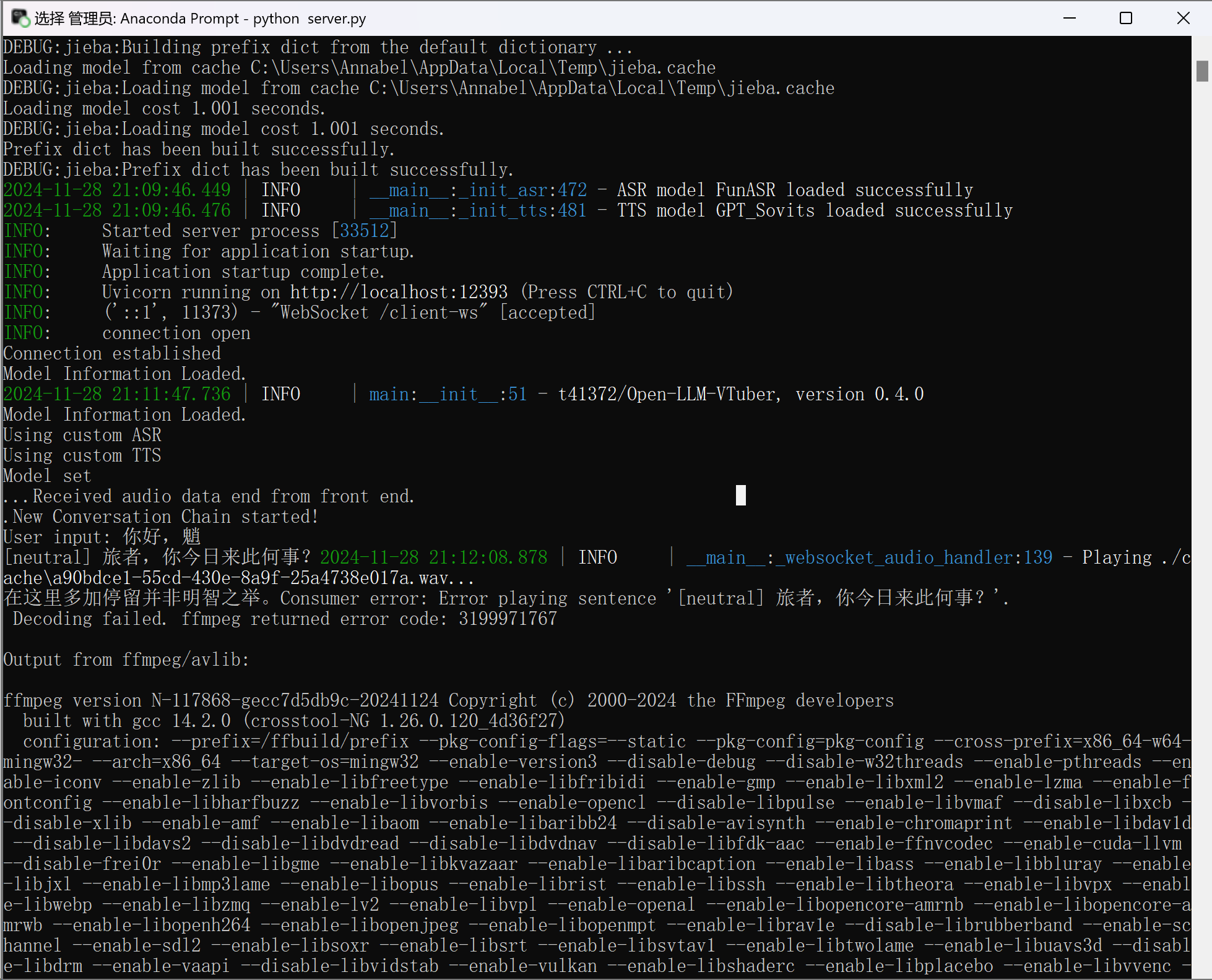
2: 修改下方GPT_Sovits中对应配置的参数:

提示GPT-Sovits加载成功但是ffmpeg提示decoding失败就是没加/tts:
如果你是用的GPT-SovitsV2整合包:
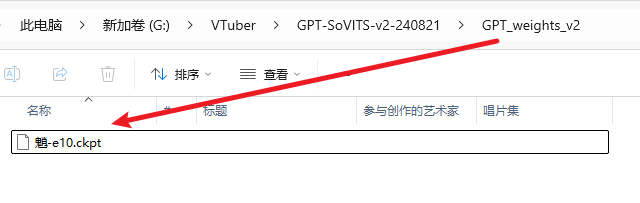
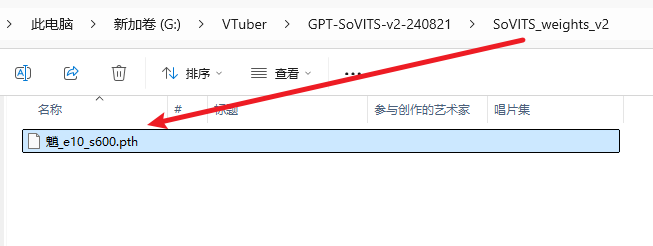
1: conf.yaml里的修改与上一步相同,不过对应的模型放在相应位置,GPT模型(ckpt后缀)放入GPT_weights_v2文件夹,SoVITS模型(pth后缀)放入SoVITS_weights_v2文件夹,参考音频如果不改位置就是放在GPT-Sovits根目录下,跟api_v2.py放在一起;
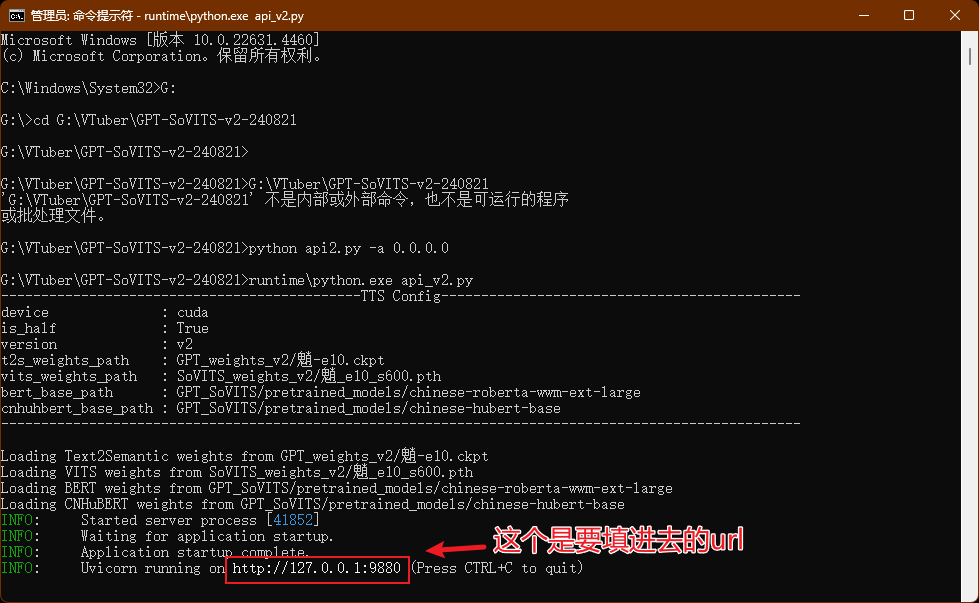
2: 运行GPT-SovitsV2,切到GPT-Sovits根目录,在prompt里面运行python api_v2.py -a 0.0.0.0,如果没反应就用整合包自带的python,在prompt里面运行runtime\python.exe api_v2.py,提示TTS config就表示加载好了,放后台就行
Bark (本地部署、较慢)
- 安装依赖:
uv pip install git+https://github.com/suno-ai/bark.git - 在
conf.yaml中设置tts_model: bark_tts - 首次启动时会自动下载所需模型
CosyVoice TTS(本地部署、较慢)
- 按照 CosyVoice 官方文档 配置并启动 WebUI
- 参考 WebUI 中的 API 文档,在
conf.yaml的cosyvoice_tts部��分进行相应配置
CosyVoice2 TTS(本地部署)
- 按照 CosyVoice 官方文档 配置环境
- 下载 CosyVoice2 模型
CosyVoice2-0.5B - 修改 CosyVoice 的
webui.py文件-
audio_output = gr.Audio(label="合成音频", autoplay=True, streaming=True)
改为 ->
audio_output = gr.Audio(label="合成音频", autoplay=True, streaming=False) -
logging.info('get instruct inference request')
set_all_random_seed(seed)
for i in cosyvoice.inference_instruct(tts_text, sft_dropdown, instruct_text, stream=stream, speed=speed):
yield (cosyvoice.sample_rate, i['tts_speech'].numpy().flatten())
改为 ->
logging.info('get instruct inference request')
prompt_speech_16k = postprocess(load_wav(prompt_wav, prompt_sr))
set_all_random_seed(seed)
for i in cosyvoice.inference_instruct2(tts_text, instruct_text, prompt_speech_16k, stream=stream, speed=speed):
yield (cosyvoice.sample_rate, i['tts_speech'].numpy().flatten())
-
- 启动 CosyVoice WebUI
- 使用命令
uv add gradio_client在本项目下安装 gradio_client - 在
conf.yaml的cosyvoice2_tts部分进行配置
目前官方只放出了CosyVoice2的基座模型——CosyVoice2-0.5B,该模型仅支持"3s极速复刻", "跨语种复刻", "自然语言控制"
- 在"3s极速复刻"模式下,需要填写 prompt_wav_upload_url 和 prompt_wav_record_url 作为参考音频,填写 prompt_text 为参考音频对应的文本
- 在"跨语种复刻"模式下,需要填写 prompt_wav_upload_url 和 prompt_wav_record_url 作为参考音频,在生成音频与参考音频语种不同时效果最好
- 在"自然语言控制"模式下,需要填写 prompt_wav_upload_url 和 prompt_wav_record_url 作为参考音频,填写 instruct_text 为控制生成的指令,如“说粤语”,“用激昂的语气”
prompt_wav_upload_url 和 prompt_wav_record_url 请填��写为相同路径 stream(流式生成)推荐填 False,因为本项目已包含语音分段合成(才不是因为填 True 会有bug
X-TTS(本地部署、较慢)
自
v0.2.4版本起可用(PR#23)
推荐使用 xtts-api-server,提供了清晰的 API 文档且部署相对简单。
Edge TTS(在线、无需 API 密钥)
- 特点:
- 响应速度快
- 需要保持网络连接
- 配置:在
conf.yaml中设置tts_model: edge_tts
Fish Audio TTS(在线、需要 API 密钥)
自
v0.3.0-beta版本起可用
- 安装依赖:
uv pip install fish-audio-sdk
- 配置步骤:
- 在 Fish Audio 注册账号并获取 API 密钥
- 选择所需声音并复制其 Reference ID
- 在
conf.yaml中设置:tts_model: fish_api_tts- 在
fish_api_tts部分填写api_key和reference_id
Azure TTS(在线、需要 API 密钥)
与 neuro-sama 相同的 TTS 服务
- 从 Azure 获取文本转语音服务的 API 密钥
- 在
conf.yaml的azure_tts部分填写相关配置
自 v0.2.5 版本起,api_key.py 已弃用,请务必在 conf.yaml 中设置 API 密钥
conf.yaml 中默认使用的是 neuro-sama 同款语音
SiliconFlow TTS(在线、需 API 密钥)
硅基流动提供的在线文本转语音服务,支持自定义音频模型和音色配置。
配置步骤
-
上传音频:
硅基流动目前有FunAudioLLM/CosyVoice2-0.5B,需要上官网上传参考音频,网址��如下: https://docs.siliconflow.cn/cn/api-reference/audio/upload-voice。 -
填写
conf.yaml配置:
在配置文件的siliconflow_tts段落中,按以下格式填写参数(示例):
siliconflow_tts:
api_url: "https://api.siliconflow.cn/v1/audio/speech" # 服务端点,固定值
api_key: "sk-yourkey" # 官网获取的API密钥
default_model: "FunAudioLLM/CosyVoice2-0.5B" # 音频模型名称(支持列表见官网)
default_voice: "speech:Dreamflowers:aaaaaaabvbbbasdas" # 音色ID,需在官网上传自定义音色后获取
sample_rate: 32000 # 输出采样率,声音异常时可尝试调整(如16000、44100)
response_format: "mp3" # 音频格式(mp3/wav等)
stream: true # 是否启用流式传输
speed: 1 # 语速(0.5~2.0,1为默认)
gain: 0 # 音量增益
MiniMax TTS(在线、需要API密钥)
MiniMax提供的在线的TTS服务,speech-02-turbo等模型具有强大的TTS性能,并且可以自由定制音色。
配置步骤
-
获取
group_id和api_key您可以通过Minimax官网注册来获取group_id和api_key,官方教程文档 -
填写
conf.yaml配置 在配置文件的minimax_tts段落中,按以下格式填写参数(示例):
minimax_tts:
group_id: '' # 你在 Minimax官网获取到 的 group_id
api_key: '' # 你在 Minimax官网获取到 的 api_key
# 支持的模型: 'speech-02-hd', 'speech-02-turbo'(推荐使用 'speech-02-turbo')
model: 'speech-02-turbo' # minimax 模型名称
voice_id: 'female-shaonv' # minimax 语音 id,默认 'female-shaonv'
# 自定义发音字典,默认为空。
# 示例: '{"tone": ["测试/(ce4)(shi4)", "危险/dangerous"]}'
pronunciation_dict: ''
其中voice_id是可以配置的声音音色,具体的支持声音列表可以查看官方文档中查询可用声音ID的部分。pronunciation_dict是可以支持的自定义发声规则,比如您可以把牛肉发音为neuro,可以用类似示例的方法来定义这个�发声规则。
ElevenLabs TTS (在线,需要API密钥)
自版本
v1.2.1起可用
ElevenLabs 提供高质量、自然流畅的文本转语音服务,支持多种语言和声音克隆功能。
功能特点
- 高质量音频:行业领先的语音合成质量
- 多语言支持:支持英语、中文、日语、韩语等多种语言
- 声音克隆:上传音频样本进行声音克隆
- 丰富的语音库:提供多种预设语音和社区语音
- 实时生成:低延迟语音合成
配置步骤
-
注册并获取API密钥
- 访问 ElevenLabs 注册账户
- 从 ElevenLabs 控制台获取您的 API 密钥
-
选择语音
- 在 ElevenLabs 控制台中浏览可用语音
- 复制您喜欢的语音的 Voice ID
- 您也可以上传音频样本进行声音克隆
-
配置
conf.yaml在配置文件的elevenlabs_tts段落中,按以下格式填写参数:
elevenlabs_tts:
api_key: 'your_elevenlabs_api_key' # 必需:您的 ElevenLabs API 密钥
voice_id: 'JBFqnCBsd6RMkjVDRZzb' # 必需:ElevenLabs 语音 ID
model_id: 'eleven_multilingual_v2' # 模型 ID(默认:eleven_multilingual_v2)
output_format: 'mp3_44100_128' # 输出音频格式(默认:mp3_44100_128)
stability: 0.5 # 语音稳定性(0.0 到 1.0,默认:0.5)
similarity_boost: 0.5 # 语音相似度增强(0.0 到 1.0,默认:0.5)
style: 0.0 # 语音风格夸张度(0.0 到 1.0,默认:0.0)
use_speaker_boost: true # 启用说话人增强以获得更好质量(默认:true)
参数说明
- api_key(必需):您的 ElevenLabs API 密钥
- voice_id(必需):语音的唯一标识符,在 ElevenLabs 控制台中找到
- model_id:要使用的 TTS 模型。可用选项:
eleven_multilingual_v2(默认)- 支持多种语言eleven_monolingual_v1- 仅英语eleven_turbo_v2- 更快的生成速度
- output_format:音频输出格式。常�用选项:
mp3_44100_128(默认)- MP3,44.1kHz,128kbpsmp3_44100_192- MP3,44.1kHz,192kbpspcm_16000- PCM,16kHzpcm_22050- PCM,22.05kHzpcm_24000- PCM,24kHzpcm_44100- PCM,44.1kHz
- stability:控制语音一致性(0.0 = 更多变化,1.0 = 更一致)
- similarity_boost:增强与原始语音的相似度(0.0 到 1.0)
- style:控制风格夸张度(0.0 = 中性,1.0 = 更具表现力)
- use_speaker_boost:启用说话人增强以提高音频质量
使用技巧
- 语音选择:先尝试预设语音,然后考虑使用声音克隆获得自定义语音
- 参数调优:调整
stability和similarity_boost以获得最佳效果 - 成本管理:ElevenLabs 按使用量收费,大量使用前请先测试
- 网络要求:需要稳定的网络连接以确保服务可用
ElevenLabs 提供免费试用额度,您可以在购买付费计划前先测试质量。