Frequently Asked Questions
Quick jump:
General Questions
I love this project. How can I help?
For regular users:
- Let us know you like the project ❤️.
- Introduce our project to friends, star us on GitHub
- Make videos about this project and post them on social media - anything goes! (It would be even better if you share them with us, saves us the trouble of searching 😎)
- Help others in the community (QQ, Discord) (this is really a big help for us!)
- Let us know in QQ, Discord groups, or other channels that real people are actually using our project!
For users familiar with the project:
- Help supplement the documentation, record problems you encounter
- If you're not sure how to edit the documentation, you can message me directly
For programmers:
- Check out the contribution guidelines, read the project issues, see if there are any issues you're interested in, and contribute.
- We are very open to Pull Requests.
How to use the xxx LLM API service?
Please fill in the relevant settings, such as API key, base url, etc., under the openai_compatible_llm settings. openai_compatible_llm accepts all LLM APIs that support the OpenAI API format.
How to choose the right LLM?
- If you want quick deployment without downloading models, we recommend using OpenAI Compatible API or Groq API
- If you want to use local deployment, we recommend choosing a suitable model based on your available VRAM
- For detailed instructions, please refer to the LLM Configuration Guide
What usage modes does the project support?
- Web mode: Access through a browser
- Window mode: Default mode for desktop clients
- Desktop pet mode: Provides a transparent background, globally top-most desktop companion experience
- For detailed explanations, please refer to the Mode Introduction
How to use the Desktop Pet mode?
- Desktop pet mode: Provides a transparent background, globally top-most desktop companion experience
- For detailed explanations, please refer to the Mode Introduction
Can this project be used on mobile phones?
Currently, mobile support is relatively weak and there are many issues.
- The project backend must run on a computer.
- The Web frontend can be accessed on mobile, but
httpsmust be configured, otherwise the microphone cannot be activated. This is a browser limitation. - On iOS, you need to keep tapping to make the speech function work normally
Two talented developers are working on a Unity version of the frontend, which hopefully will solve these issues. We look forward to the day they complete it.
How to get the latest version of the frontend?
- Currently, the frontend does not support automatic updates. You can follow the Github Release page to get the latest version.
- For detailed instructions, please refer to the Mode Introduction
Backend Error Issues
uv cannot be found after installation
- If you installed uv using
wingetorcurl, you need to restart the command line or reload the shell configuration file for the environment variables to take effect. - For detailed instructions, please refer to Quick Start
What to do if I encounter proxy-related issues?
Keywords: HTTP, SSL error, timeout, Failed to connect to github.com port 443 after 21, etc.
- If you're in mainland China, it's recommended to enable a proxy to download resources
- If local services are inaccessible, you need to set up proxy bypass for local addresses
- For detailed instructions, please refer to Quick Start
What to do if I encounter the "Error calling the chat endpoint..." error?
The AI will read out the error message, and no matter what you say, it will only repeat sentences starting with this phrase.
Error calling the chat endpoint
This indicates that the large language model (LLM) call has failed. When this problem occurs, it means Open-LLM-VTuber failed in the process of calling the large language model API you specified. Please check the relevant settings in llm_configs to ensure that the model name, endpoint url (base_url), and API key are correct.
Error Message Analysis
For security considerations, the frontend page does not display the full error details. Please go to the backend to read the relevant error messages.
1. Unable to connect to LLM API
Error calling the chat endpoint: Connection error. Failed to connect to the LLM API. Check the configurations and the reachability of the LLM backend. See the logs for details. Troubleshooting with documentation
This means that the LLM you set up cannot be accessed normally.
- Please check if your
base_urlis correctly filled in. - Please check if the filled API is available and can be accessed normally
- If you're using Ollama, make sure Ollama is started. Visit
http://localhost:11434/(or your Ollama address, remove the/v1at the end) in a browser. If it doesn't display text similar toOllama is running, it means your Ollama is not started or cannot be accessed by the local machine. - If you're using LM Studio, make sure the LM Studio Server is properly started and the model is loaded.
- If your proxy software doesn't bypass local addresses, it will cause Ollama or other local LLM inference engines to fail to connect. Try temporarily disabling the proxy, or refer to the previous text to set up proxy bypass for local addresses.
2. Model name filled in incorrectly
- Please ensure that the model name you filled in is correct. Note the difference between colon
:and:, and note that there are generally no spaces in model names. - For Ollama users, please ensure that the model name you filled in is one of the models shown by the
ollama listcommand. - If the error message prompts
Model not found, try pulling it..., please useollama listto check the names of installed models, and ensure that the model name in the configuration file matches exactly with one in the list. - LM Studio users, please ensure that the model you filled in is the one loaded into memory.
3. Rate limit exceeded
Error calling the chat endpoint: Rate limit exceeded
You're chatting too intensely, you've exceeded the rate limit of the LLM API you're using.
Common Causes and Solutions:
- Check if the Ollama service is running normally. If you're using another API, please ensure the API can be accessed normally, the API key is correct, and the network is smooth.
- Confirm that the model name matches exactly with what's listed by
ollama list
- For detailed instructions, please refer to Quick Start
What to do if I encounter the AttributeError: 'NoneType' object has no attribute 'emo_str' error?
- The model name in
model_dict.jsondoesn't correspond to the one inconf.yaml model_dict.jsonformat error (Error decoding JSON from model dictionary file at model_dict.json)
What to do if I encounter the error while attempting to bind on address ('127.0.0.1',12393):Usually each socket address (protocol/network address/port) is only allowed to be used once. error?
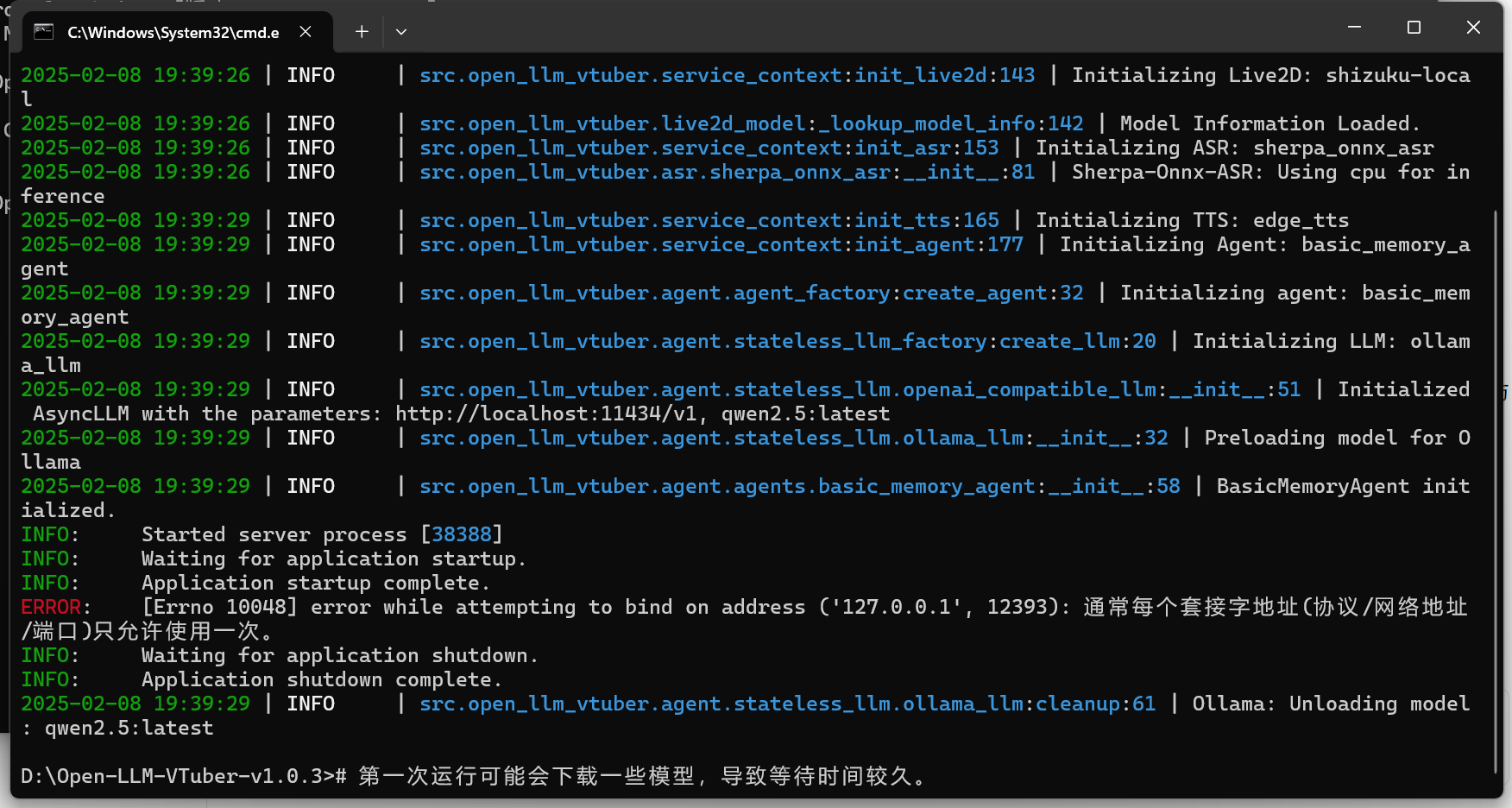
Please don't run two Open-LLM-VTuber backends on the same computer, it doesn't make sense. Please close the other one.
If you don't think you've opened two Open-LLM-VTuber backends, try restarting your computer.
This error message means that the :12393 port is already occupied. This is the default port occupied by this project's backend, and generally no other programs would occupy this port.
If you absolutely must run two Open-LLM-VTuber backends simultaneously, or if another application has occupied this port, you can modify the port bound by the project in the port setting under system_config in the conf.yaml file.
Web/Client Related
What to do if Web displays {"detail": "Not Found"}?

- The frontend code hasn't been pulled to local. This error appears when you haven't obtained the complete project code. Please run
git submodule update --init --recursivein the project directory to pull the project code. - For details, please refer to the two ways of obtaining project code mentioned in Quick Start/1. Get Project Code.
What to do if using a remote Live2D model link results in Failed to load LiveD model: Error: Network error?
- This is usually because Web using HTTP protocol cannot load HTTPS resources
- You can solve this by allowing the website to load insecure content in browser settings:
- Chrome: Click the shield icon on the right side of the address bar -> Site settings -> Insecure content -> Allow
- Firefox: Click the lock icon on the left side of the address bar -> Turn off connection protection
- Edge: Click the lock icon on the right side of the address bar -> Site permissions -> Insecure content -> Allow
What to do if the microphone is not working?
- Please ensure that you have granted microphone usage permission to the browser or application
- Check if the microphone input volume is appropriate - sound that's too low or too short may not trigger voice detection. You can adjust the detection threshold in settings, for detailed settings please refer to Web Mode
- If you're using the Electron desktop application, try restarting the application.
- If all of the above methods are ineffective, you can visit https://www.vad.ricky0123.com/ to test microphone functionality. If this website also can't use the microphone normally, it might be a system audio setting or hardware issue
What to do if the desktop client can't be installed (Windows has protected your PC) or prompts "damaged"?
- Windows users can click "More info" and then choose "Run anyway"
- macOS users need to adjust system settings and execute specific commands
- For detailed solutions, please refer to Mode Introduction
What to do if microphone/camera/screen recording can't be used when accessing the Web interface remotely (Failed to start screen capture: NotSupportedError: Not supported)?
- This is because these features require a secure context (HTTPS or localhost)
- If remote use is needed, HTTPS must be configured for the Web server
- For detailed instructions, please refer to Mode Introduction
What to do if voice functionality is abnormal on iOS devices?
- This is a known issue caused by iOS security restrictions
- You need to keep tapping to make the speech function work normally
- For detailed instructions, please refer to Mode Introduction